
In distributed systems, asynchronous communication is often covered by a message broker. This is intended to achieve a decoupling between two services that can be scaled separately under certain circumstances. Communication over a message broker is always inherently divided into at least two parts: the producer and consumer.
A producer creates messages, as shown in Figure 1, while a consumer processes them.
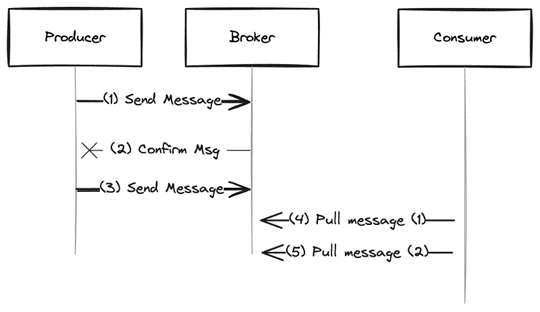
Fig.1: A simple message exchange
The message broker is often a stateful system – a type of database – and mediates messages between the producer and consumer. As a stateful system, a message broker is tasked with storing messages and making them available for retrieval. A producer writes messages to the broker, while a consumer can read them at any time. Exactly once means that the producer produces exactly one message and the consumer processes it exactly once. So very simple, isn’t it?
It can be that simple
As communication between the systems takes place over a network level, it isn’t guaranteed that the systems have the same level of knowledge. There must be a feedback channel that confirms individual operations in order to share a status. This is the only way to make sure that created messages have been received and processed correctly. When updated, the flow looks more like Figure 2.
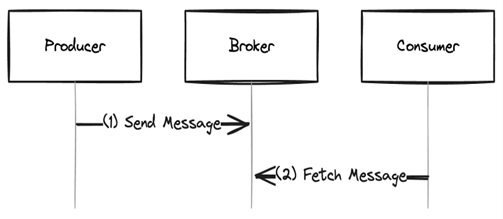
Fig. 2: Confirmations are used to share status between systems
If a producer creates a message that will be read by the consumer, the consumer needs confirmation (Fig. 2, step 2). This is the only way for the producer to know that the message is correctly persisted in the broker and that it doesn’t need to be retransmitted.

Develop state-of-the-art serverless applications?
Explore the Serverless Development Track
The consumer reads the message and processes it. If processing is completed without errors, the consumer confirms it and the broker doesn’t have to deliver the message again.
Always trouble with communication
Unfortunately, with distributed communication over a network, various communication channels can sometimes break off or errors can occur. This can happen at many points: during creation, before consumption, and afterwards. This exact characteristic makes it difficult, or even impossible, to achieve exactly-once semantics.
Suppose a producer produces a message (Fig. 3). To ensure that the broker has saved it, the producer waits for confirmation. If this is not received, there is no guarantee that the broker will actually deliver this message.
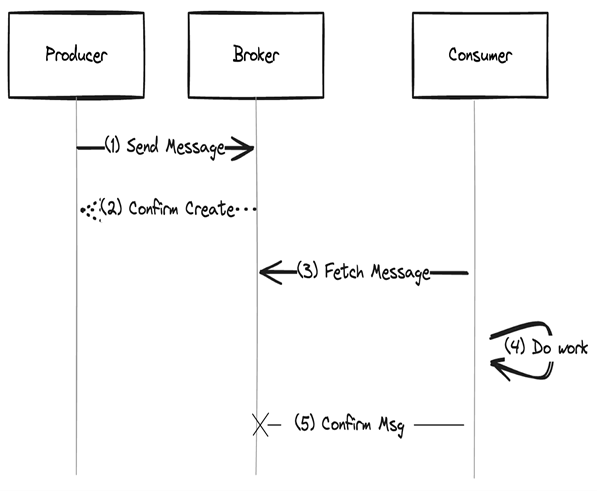
Fig. 3: The producer receives no confirmation and sends the message again
The producer must send this message again. This is exactly what happened in Figure 3, step 2, which is why the producer sends another message with the same content in step 3. Since there are now two messages, the consumer processes both messages in steps 4 and 5, probably not “exactly once”. The message is transmitted by the retry mechanism “at least once” – at least once, not exactly once. As you can see in the image, this is because the producer transmits the same message twice to make sure that the broker has confirmed it at least once. This is the only way to ensure that the message isn’t lost.
Of course, the confirmation can also be ignored. Step 2 can be omitted, so a retry system would be missing. Therefore, the producer transmits a message without waiting for confirmation from the broker. If the broker cannot process or save the message, it has no way of acknowledging failure or a successful operation. The message would be transmitted “at most once” – at most once, or not at all. Exactly once is fundamentally a problem for distributed applications that work with confirmations.
Unfortunately, this isn’t the end of the story when the message is end-to-end, for instance, from the producer to the consumer. There’s also a consumer in this kind of system, which in turn has to process the messages once. Even when it’s guaranteed that the producer generates a message once, one-time processing isn’t a guarantee.
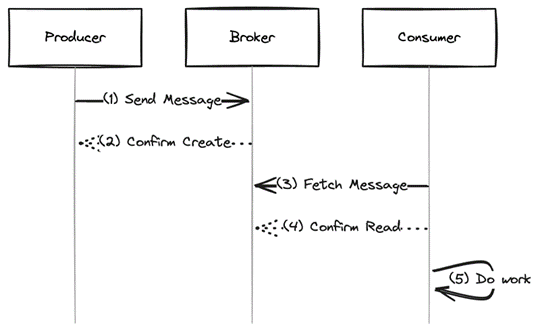
Fig. 4: A consumer processes the message and then attempts to confirm it
It is possible for a consumer to read the message in step 3 and process it correctly in step 4, as shown in Figure 4. The confirmation is lost in step 5. This results in the message being processed several times, but at least once.
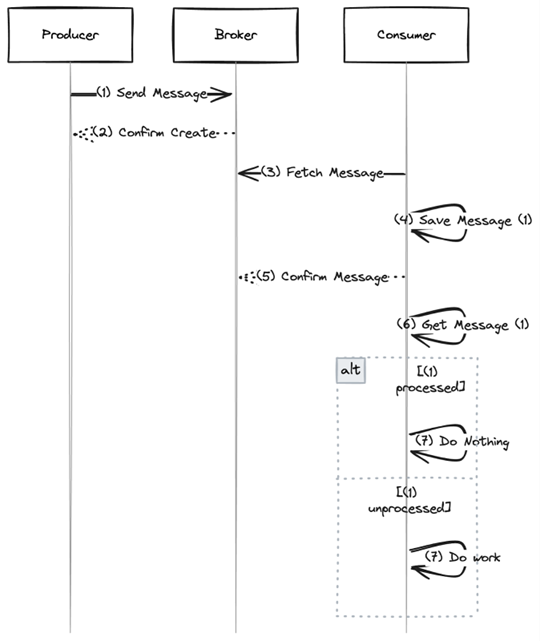
Fig. 5: A consumer confirms the message before it is processed
Conversely, confirming the message before processing is also possible. The consumer loads the message and directly confirms it. Then, the message is processed in step 5 from Figure 5. If processing fails now, the message has already been confirmed in step 4 and won’t be read in again. The message has been processed at most once or not at all.
As you can see, it’s easy to create at-most-once and at-least-once semantics in the various configurations on both the producer and consumer side. However, exactly once is a difficult problem because of the distributed system. Or is it even impossible?
Learn more about Serverless Architecture ConferenceSTAY TUNED!
Solutions must be found
In order to achieve exactly-once semantics, processing an application’s messages must support a certain property: Idempotency. Idempotency means that an operation, no matter how often it’s processed, always produces the same result. An example of this principle is setting a variable in a program’s code. You can implement this with setters or relative mutations.
For example, setAge or incrementAge. The operation person.setAge(14); can be executed any number of times in succession. The result always remains the same; it is always 14. person.incrementAge(1), on the other hand, is not idempotent. If this method is executed several times in succession, it will have different results. Namely, it will give one year more after each execution. This property of idempotency is the key to establishing exactly-once semantics.
Applied to the previous systems, this means that at-least-once semantics with the idempotence property can lead to exactly-once processing. The confirmation system described above shows how at-least-once semantics can be implemented. What’s missing is a system of idempotence in processing. But how can processing messages be made idempotent?
To achieve this, the consumer must be able to obtain a local, synchronized state. In order to obtain the state of a message, it must be uniquely identifiable. This is the only way to enable retrieval and deduplication of the message.
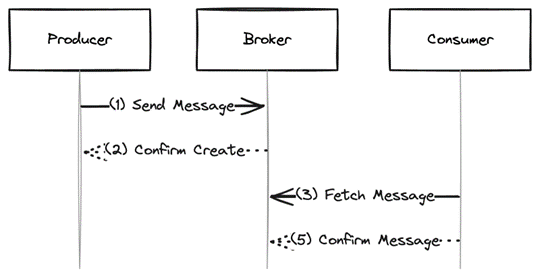
Fig. 6: Idempotent processing
Unlike before, first the consumer saves the message in a local state storage with each call in Figure 6, step 4. At this point, if the message already exists locally, you do not have to save it again. The message is confirmed in step 5. If the confirmation fails and the message is transmitted again, this isn’t a problem. The message can be prevented from being saved again in step 4. This is where idempotency comes to life. When processing, the consumer can decide for themselves if processing is necessary, for example, by introducing a status for a message and querying it locally in step 6. If this is already set to Processed, nothing needs to be done. Conversely, a processed message must correctly update the status.
Conclusion
Distributed systems have a fundamental problem regarding creating exactly-once semantics. At the infrastructure level, a choice can be made between at least once or at most once. Only with the idempotency property can we be sure that messages are processed exactly once from end-to-end at the application level.
Of course, this doesn’t come for free. The application itself has to take over managing messages and their status. This isn’t really exactly once either, but it comes very close as a result of the idempotence property.




